diagnosis_qc_gigamuga_12_batches
Hao He
2020-11-06
- Genotype diagnostics for diversity outbred mice
- library
- Generate json file for all 12 batches
- Missing data per sample
- Sexes
- Sample duplicates
- Array intensities and Genotype frequencies
- Crossover counts and Genotyping error LOD scores
- Missing data in Markers and Genotype frequencies Markers
- Remove bad samples
Last updated: 2020-11-06
Checks: 7 0
Knit directory: csna_workflow/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20190918) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 553d37f. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: analysis/.Rhistory
Untracked files:
Untracked: analysis/.nfs0000000135a08b9b00002448
Untracked: analysis/.nfs0000000135a08ba50000244a
Untracked: analysis/07_do_diversity_report.Rmd
Untracked: analysis/19_qtl_analysis_RTG20_GS_a1.R
Untracked: analysis/19_qtl_analysis_RTG20_GS_a1.err
Untracked: analysis/19_qtl_analysis_RTG20_GS_a1.out
Untracked: analysis/19_qtl_analysis_RTG20_GS_a1.sh
Untracked: analysis/19_qtl_analysis_RTG20_GS_a2.R
Untracked: analysis/19_qtl_analysis_RTG20_GS_a2.err
Untracked: analysis/19_qtl_analysis_RTG20_GS_a2.out
Untracked: analysis/19_qtl_analysis_RTG20_GS_a2.sh
Untracked: analysis/19_qtl_analysis_RTG20_GS_a3.R
Untracked: analysis/19_qtl_analysis_RTG20_GS_a3.err
Untracked: analysis/19_qtl_analysis_RTG20_GS_a3.out
Untracked: analysis/19_qtl_analysis_RTG20_GS_a3.sh
Untracked: analysis/19_qtl_analysis_RTG20_GS_a4.R
Untracked: analysis/19_qtl_analysis_RTG20_GS_a4.err
Untracked: analysis/19_qtl_analysis_RTG20_GS_a4.out
Untracked: analysis/19_qtl_analysis_RTG20_GS_a4.sh
Untracked: analysis/19_qtl_analysis_RTG20_G_a1.R
Untracked: analysis/19_qtl_analysis_RTG20_G_a1.err
Untracked: analysis/19_qtl_analysis_RTG20_G_a1.out
Untracked: analysis/19_qtl_analysis_RTG20_G_a1.sh
Untracked: analysis/19_qtl_analysis_RTG20_G_a2.R
Untracked: analysis/19_qtl_analysis_RTG20_G_a2.err
Untracked: analysis/19_qtl_analysis_RTG20_G_a2.out
Untracked: analysis/19_qtl_analysis_RTG20_G_a2.sh
Untracked: analysis/19_qtl_analysis_RTG20_G_a3.R
Untracked: analysis/19_qtl_analysis_RTG20_G_a3.err
Untracked: analysis/19_qtl_analysis_RTG20_G_a3.out
Untracked: analysis/19_qtl_analysis_RTG20_G_a3.sh
Untracked: analysis/19_qtl_analysis_RTG20_G_a4.R
Untracked: analysis/19_qtl_analysis_RTG20_G_a4.err
Untracked: analysis/19_qtl_analysis_RTG20_G_a4.out
Untracked: analysis/19_qtl_analysis_RTG20_G_a4.sh
Untracked: analysis/csna_image.sif
Untracked: analysis/scripts/
Untracked: analysis/temp/
Untracked: analysis/workflow_proc.R
Untracked: analysis/workflow_proc.sh
Untracked: analysis/workflow_proc.stderr
Untracked: analysis/workflow_proc.stdout
Untracked: code/reconst_utils.R
Untracked: data/69k_grid_pgmap.RData
Untracked: data/FinalReport/
Untracked: data/GCTA/
Untracked: data/GM/
Untracked: data/Jackson_Lab_11_batches/
Untracked: data/Jackson_Lab_12_batches/
Untracked: data/Jackson_Lab_Bubier_MURGIGV01/
Untracked: data/Jackson_Lab_Gagnon/
Untracked: data/RTG/
Untracked: data/cc_variants.sqlite
Untracked: data/marker_grid_0.02cM_plus.txt
Untracked: data/mouse_genes_mgi.sqlite
Untracked: data/pheno/
Untracked: output/AfterQC_Percent_missing_genotype_data.pdf
Untracked: output/AfterQC_Proportion_matching_genotypes_after_removal_of_bad_samples.pdf
Untracked: output/AfterQC_Proportion_matching_genotypes_before_removal_of_bad_samples.pdf
Untracked: output/AfterQC_number_crossover.pdf
Untracked: output/DO_Gigamuga_chr2_WSB_G21.png
Untracked: output/DO_Gigamuga_chr2_WSB_G22.png
Untracked: output/DO_Gigamuga_chr2_WSB_G23.png
Untracked: output/DO_Gigamuga_chr2_WSB_G25.png
Untracked: output/DO_Gigamuga_chr2_WSB_G29.png
Untracked: output/DO_Gigamuga_chr2_WSB_G30.png
Untracked: output/DO_Gigamuga_chr2_WSB_G31.png
Untracked: output/DO_Gigamuga_chr2_WSB_G32.png
Untracked: output/DO_Gigamuga_chr2_WSB_G33.png
Untracked: output/DO_Gigamuga_founder_proportions_G21.png
Untracked: output/DO_Gigamuga_founder_proportions_G22.png
Untracked: output/DO_Gigamuga_founder_proportions_G23.png
Untracked: output/DO_Gigamuga_founder_proportions_G25.png
Untracked: output/DO_Gigamuga_founder_proportions_G29.png
Untracked: output/DO_Gigamuga_founder_proportions_G30.png
Untracked: output/DO_Gigamuga_founder_proportions_G31.png
Untracked: output/DO_Gigamuga_founder_proportions_G32.png
Untracked: output/DO_Gigamuga_founder_proportions_G33.png
Untracked: output/DO_Gigamuga_founder_proportions_chr2_G21.png
Untracked: output/DO_Gigamuga_founder_proportions_chr2_G22.png
Untracked: output/DO_Gigamuga_founder_proportions_chr2_G23.png
Untracked: output/DO_Gigamuga_founder_proportions_chr2_G25.png
Untracked: output/DO_Gigamuga_founder_proportions_chr2_G29.png
Untracked: output/DO_Gigamuga_founder_proportions_chr2_G30.png
Untracked: output/DO_Gigamuga_founder_proportions_chr2_G31.png
Untracked: output/DO_Gigamuga_founder_proportions_chr2_G32.png
Untracked: output/DO_Gigamuga_founder_proportions_chr2_G33.png
Untracked: output/DO_recom_block_size_G21.png
Untracked: output/DO_recom_block_size_G22.png
Untracked: output/DO_recom_block_size_G23.png
Untracked: output/DO_recom_block_size_G25.png
Untracked: output/DO_recom_block_size_G29.png
Untracked: output/DO_recom_block_size_G30.png
Untracked: output/DO_recom_block_size_G31.png
Untracked: output/DO_recom_block_size_G32.png
Untracked: output/DO_recom_block_size_G33.png
Untracked: output/Histgram_Prj01_RL-Acquisition_preqc_02142020.pdf
Untracked: output/Histgram_Prj01_RL-Reversal_preqc_02142020.pdf
Untracked: output/Histgram_Prj02_Sensitization_preqc_02142020.pdf
Untracked: output/Histgram_Prj04_IVSA_preqc_02142020.pdf
Untracked: output/Novelty_residuals_RankNormal_datarelease_12182019-69k-genelist.csv
Untracked: output/Novelty_residuals_RankNormal_datarelease_12182019-69k-variantlist.csv
Untracked: output/Novelty_residuals_RankNormal_datarelease_12182019-genelist.csv
Untracked: output/Novelty_residuals_RankNormal_datarelease_12182019-variantlist.csv
Untracked: output/Percent_genotype_errors_obs_vs_predicted.pdf
Untracked: output/Percent_missing_genotype_data.pdf
Untracked: output/Percent_missing_genotype_data_per_marker.pdf
Untracked: output/Proportion_matching_genotypes_after_removal_of_bad_samples.pdf
Untracked: output/Proportion_matching_genotypes_after_removal_samples_percent_missing_5.pdf
Untracked: output/Proportion_matching_genotypes_before_removal_of_bad_samples.pdf
Untracked: output/Proportion_matching_genotypes_before_removal_samples.pdf
Untracked: output/RTG/
Untracked: output/blup/
Untracked: output/condi.m2.Novelty_residuals_RankNormal_datarelease_12182019_genomescan.pdf
Untracked: output/condi.m2.qtl.blup_Novelty_residuals_RankNormal_datarelease_12182019_coeffgeneplot.pdf
Untracked: output/condi.m2.qtl.out.RData
Untracked: output/conditional.69k.Novelty_residuals_RankNormal_datarelease_12182019-genelist.csv
Untracked: output/conditional.69k.Novelty_residuals_RankNormal_datarelease_12182019-variantlist.csv
Untracked: output/conditional.Novelty_residuals_RankNormal_datarelease_12182019-genelist.csv
Untracked: output/conditional.Novelty_residuals_RankNormal_datarelease_12182019-variantlist.csv
Untracked: output/conditional.m2.69k.Novelty_residuals_RankNormal_datarelease_12182019.RData
Untracked: output/conditional.m2.69k.Novelty_residuals_RankNormal_datarelease_12182019_coeffgeneplot.pdf
Untracked: output/conditional.m2.69k.Novelty_residuals_RankNormal_datarelease_12182019_genomescan.pdf
Untracked: output/conditional.m2.Novelty_residuals_RankNormal_datarelease_12182019.RData
Untracked: output/conditional.m2.Novelty_residuals_RankNormal_datarelease_12182019_coeffgeneplot.pdf
Untracked: output/conditional.m2.Novelty_residuals_RankNormal_datarelease_12182019_genomescan.pdf
Untracked: output/conditional.m2.qtl.out.RData
Untracked: output/conditional_m2.Novelty_residuals_RankNormal_datarelease_07302918_genomescan.pdf
Untracked: output/conditional_m2.Novelty_residuals_RankNormal_datarelease_12182019_genomescan.pdf
Untracked: output/genotype_error_marker.pdf
Untracked: output/genotype_frequency_marker.pdf
Untracked: output/m1.Novelty_resids_datarelease_07302918.RData
Untracked: output/m1.Novelty_resids_datarelease_07302918_coeffgeneplot.pdf
Untracked: output/m1.Novelty_resids_datarelease_07302918_genomescan.pdf
Untracked: output/m1.Novelty_resids_datarelease_12182019.RData
Untracked: output/m1.Novelty_resids_datarelease_12182019_coeffgeneplot.pdf
Untracked: output/m1.Novelty_resids_datarelease_12182019_genomescan.pdf
Untracked: output/m1.Novelty_residuals_RankNormal_datarelease_07302918.RData
Untracked: output/m1.Novelty_residuals_RankNormal_datarelease_07302918_genomescan.pdf
Untracked: output/m1.Novelty_residuals_RankNormal_datarelease_12182019.RData
Untracked: output/m1.Novelty_residuals_RankNormal_datarelease_12182019_coeffgeneplot.pdf
Untracked: output/m1.Novelty_residuals_RankNormal_datarelease_12182019_genomescan.pdf
Untracked: output/m2.69k.Novelty_residuals_RankNormal_datarelease_12182019.RData
Untracked: output/m2.69k.Novelty_residuals_RankNormal_datarelease_12182019_coeffgeneplot.pdf
Untracked: output/m2.69k.Novelty_residuals_RankNormal_datarelease_12182019_genomescan.pdf
Untracked: output/m2.69k.Prj01_RL-Acquisition_preqc_02142020.RData
Untracked: output/m2.69k.Prj01_RL-Reversal_preqc_02142020.RData
Untracked: output/m2.69k.Prj02_Sensitization_preqc_02142020.RData
Untracked: output/m2.69k.Prj04_IVSA_preqc_02142020.RData
Untracked: output/m2.Novelty_resids_datarelease_07302918.RData
Untracked: output/m2.Novelty_resids_datarelease_07302918_genomescan.pdf
Untracked: output/m2.Novelty_resids_datarelease_12182019.RData
Untracked: output/m2.Novelty_resids_datarelease_12182019_coeffgeneplot.pdf
Untracked: output/m2.Novelty_resids_datarelease_12182019_genomescan.pdf
Untracked: output/m2.Novelty_residuals_RankNormal_datarelease_07302918.RData
Untracked: output/m2.Novelty_residuals_RankNormal_datarelease_07302918_genomescan.pdf
Untracked: output/m2.Novelty_residuals_RankNormal_datarelease_12182019.RData
Untracked: output/m2.Novelty_residuals_RankNormal_datarelease_12182019_coeffgeneplot.pdf
Untracked: output/m2.Novelty_residuals_RankNormal_datarelease_12182019_genomescan.pdf
Untracked: output/m2.Prj01_RL-Acquisition_preqc_02142020.RData
Untracked: output/m2.Prj01_RL-Acquisition_preqc_02142020_qtl2scan.pdf
Untracked: output/m2.Prj01_RL-Reversal_preqc_02142020.RData
Untracked: output/m2.Prj01_RL-Reversal_preqc_02142020_qtl2scan.pdf
Untracked: output/m2.Prj02_Sensitization_preqc_02142020.RData
Untracked: output/m2.Prj02_Sensitization_preqc_02142020_qtl2scan.pdf
Untracked: output/m2.Prj04_IVSA_preqc_02142020.RData
Untracked: output/m2.Prj04_IVSA_preqc_02142020_qtl2scan.pdf
Untracked: output/m3.Novelty_resids_datarelease_07302918.RData
Untracked: output/m3.Novelty_resids_datarelease_07302918_genomescan.pdf
Untracked: output/m3.Novelty_resids_datarelease_12182019.RData
Untracked: output/m3.Novelty_resids_datarelease_12182019_coeffgeneplot.pdf
Untracked: output/m3.Novelty_resids_datarelease_12182019_genomescan.pdf
Untracked: output/m3.Novelty_residuals_RankNormal_datarelease_07302918.RData
Untracked: output/m3.Novelty_residuals_RankNormal_datarelease_07302918_genomescan.pdf
Untracked: output/m3.Novelty_residuals_RankNormal_datarelease_12182019.RData
Untracked: output/m3.Novelty_residuals_RankNormal_datarelease_12182019_coeffgeneplot.pdf
Untracked: output/m3.Novelty_residuals_RankNormal_datarelease_12182019_genomescan.pdf
Untracked: output/num.geno.pheno.in.Novelty_resids_datarelease_07302918.csv
Untracked: output/num.geno.pheno.in.Novelty_resids_datarelease_12182019.csv
Untracked: output/num.geno.pheno.in.Novelty_residuals_RankNormal_datarelease_07302918.csv
Untracked: output/num.geno.pheno.in.Novelty_residuals_RankNormal_datarelease_12182019.csv
Untracked: output/number_crossover.pdf
Untracked: output/permu/
Untracked: output/prop_across_generation_chr_p.RData
Unstaged changes:
Modified: README.md
Modified: _workflowr.yml
Deleted: analysis/01_geneseek2qtl2.R
Deleted: analysis/02_geneseek2intensity.R
Deleted: analysis/03_firstgm2genoprobs.R
Deleted: analysis/04_diagnosis_qc_gigamuga_11_batches.Rmd
Deleted: analysis/04_diagnosis_qc_gigamuga_nine_batches.R
Deleted: analysis/04_diagnosis_qc_gigamuga_nine_batches.Rmd
Deleted: analysis/05_after_diagnosis_qc_gigamuga_11_batches.Rmd
Deleted: analysis/05_after_diagnosis_qc_gigamuga_nine_batches.R
Deleted: analysis/05_after_diagnosis_qc_gigamuga_nine_batches.Rmd
Deleted: analysis/06_final_pr_apr_69K.R
Deleted: analysis/07.1_html_founder_prop.R
Deleted: analysis/07_recomb_size_founder_prop.R
Deleted: analysis/07_recomb_size_founder_prop.Rmd
Deleted: analysis/08_gcta_herit.R
Deleted: analysis/09_qtlmapping.R
Deleted: analysis/10_qtl_permu.R
Deleted: analysis/11_qtl_blup.R
Deleted: analysis/12_plot_69k_qtl_mapping_2.Rmd
Deleted: analysis/12_plot_qtl_mapping_1.Rmd
Deleted: analysis/12_plot_qtl_mapping_2.Rmd
Deleted: analysis/13_plot_69k_conditional_m2_qtlmapping.Rmd
Deleted: analysis/13_plot_conditional_m2_qtlmapping.Rmd
Deleted: analysis/16_diagnosis_qc_gigamuga_gagnon.Rmd
Deleted: analysis/16_diagnosis_qc_gigamuga_gagnon2.Rmd
Deleted: analysis/17_plot_qtl_mapping.Rmd
Deleted: analysis/run_01_geneseek2qtl2.R
Deleted: analysis/run_02_geneseek2intensity.R
Deleted: analysis/run_03_firstgm2genoprobs.R
Deleted: analysis/run_04_diagnosis_qc_gigamuga_nine_batches.R
Deleted: analysis/run_05_after_diagnosis_qc_gigamuga_nine_batches.R
Deleted: analysis/run_06_final_pr_apr_69K.R
Deleted: analysis/run_07.1_html_founder_prop.R
Deleted: analysis/run_07_recomb_size_founder_prop.R
Deleted: analysis/run_08_gcta_herit.R
Deleted: analysis/run_09_qtlmapping.R
Deleted: analysis/run_10_qtl_permu.R
Deleted: analysis/run_11_qtl_blup.R
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/04_diagnosis_qc_gigamuga_12_batches.Rmd) and HTML (docs/04_diagnosis_qc_gigamuga_12_batches.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 553d37f | xhyuo | 2020-11-06 | 12_batches_report |
| html | 6610ab1 | xhyuo | 2020-11-05 | Build site. |
| Rmd | 8d3b7b7 | xhyuo | 2020-11-04 | 12_batches_before_afterQC |
| html | 070d088 | xhyuo | 2020-11-04 | Build site. |
| Rmd | 1b61cb6 | xhyuo | 2020-11-04 | 12_batches_before_afterQC |
| html | 2ef6747 | xhyuo | 2020-11-04 | Build site. |
| Rmd | 9a8cab2 | xhyuo | 2020-11-04 | 12_batches |
| html | c1326cd | xhyuo | 2020-11-04 | Build site. |
| Rmd | 2f3a962 | xhyuo | 2020-11-04 | 12_batches |
Genotype diagnostics for diversity outbred mice
We first load the R/qtl2 package and the data. We’ll also load the R/broman package for some utilities and plotting functions, and R/qtlcharts for interactive graphs.
library
library(broman)
library(qtl2)
library(qtlcharts)
library(ggplot2)
library(ggrepel)
library(DOQTL)
library(mclust)
library(tidyverse)
library(reshape2)
library(DT)
source("code/reconst_utils.R")
options(stringsAsFactors = F)Generate json file for all 12 batches
#total sample id
#load json file for the 12 batches
gm <- get(load("data/Jackson_Lab_12_batches/gm_12batches.RData"))
gmObject of class cross2 (crosstype "do")
Total individuals 3282
No. genotyped individuals 3282
No. phenotyped individuals 3282
No. with both geno & pheno 3282
No. phenotypes 1
No. covariates 3
No. phenotype covariates 0
No. chromosomes 20
Total markers 112729
No. markers by chr:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
8555 8666 6420 6615 6571 6444 6294 5677 5870 5447 6352 5167 5274 5039 4555 4369
17 18 19 X
4330 4002 3108 3974 Missing data per sample
percent_missing <- n_missing(gm, "ind", "prop")*100
miss_dat <- data.frame(Mouse=seq_along(percent_missing),
id = names(percent_missing),
Percent_missing_genotype_data = percent_missing,
batch = as.character(do.call(rbind.data.frame,
strsplit(ind_ids(gm), "_"))[,5]),
labels = as.character(do.call(rbind.data.frame,
strsplit(ind_ids(gm), "V01_"))[,2]))
miss_dat <- miss_dat %>%
mutate(labels2 = case_when(
percent_missing <= 10 ~ "",
TRUE ~ labels
))
#iplot
iplot(miss_dat$Mouse,
miss_dat$Percent_missing_genotype_data,
indID=paste0(miss_dat$labels, " (", round(miss_dat$Percent_missing_genotype_data,2), "%)"),
chartOpts=list(xlab="Mouse",
ylab="Percent missing genotype data",
ylim=c(0, 100)))Set screen size to height=700 x width=1000#save into pdf
pdf(file = "data/Jackson_Lab_12_batches/Percent_missing_genotype_data.pdf", width = 20, height = 20)
# Change point shapes and colors
p <- ggplot(data = miss_dat,
aes(x=Mouse, y=Percent_missing_genotype_data, color = batch)) +
geom_point() +
geom_hline(yintercept=5, linetype="solid", color = "red") +
geom_text_repel(aes(label=labels2), vjust = 0, nudge_y = 0.01, show.legend = FALSE, size=3) +
theme(text = element_text(size = 20))
p
dev.off()png
2 p
| Version | Author | Date |
|---|---|---|
| c1326cd | xhyuo | 2020-11-04 |
save(percent_missing,
file = "data/Jackson_Lab_12_batches/percent_missing_id.RData")Sexes
xint <- read_csv_numer("data/Jackson_Lab_12_batches/Jackson_Lab_12_batches_qtl2_chrXint.csv", transpose=TRUE)
yint <- read_csv_numer("data/Jackson_Lab_12_batches/Jackson_Lab_12_batches_qtl2_chrYint.csv", transpose=TRUE)
# Gigamuga marker annotation file from UNC.
gm_marker_file = "http://csbio.unc.edu/MUGA/snps.gigamuga.Rdata" #FIXED
# Read in the UNC GigaMUGA SNPs and clusters.
load(url(gm_marker_file))
#subset down to gm
snps$marker = as.character(snps$marker)
#load the intensities.fst.RData
load("data/Jackson_Lab_12_batches/intensities.fst.RData")
#X and Y channel
X <- result[result$channel == "X",]
rownames(X) <- X$snp
X <- X[,c(-1,-2)]
Y <- result[result$channel == "Y",]
rownames(Y) <- Y$snp
Y <- Y[,c(-1,-2)]
#determine predict.sex
predict.sex = determine_sex_chry_m(x = X, y = Y, markers = snps)$sex
gm$covar <- gm$covar %>%
mutate(id = rownames(gm$covar)) %>%
left_join(data.frame(id = names(predict.sex),
predict.sex = predict.sex,stringsAsFactors = F))Joining, by = "id"rownames(gm$covar) <- gm$covar$id
#sex order
sex <- gm$covar[rownames(xint),"sex"]
x_pval <- apply(xint, 2, function(a) t.test(a ~ sex)$p.value)
y_pval <- apply(yint, 2, function(a) t.test(a ~ sex)$p.value)
xint_ave <- rowMeans(xint[, x_pval < 0.05/length(x_pval)], na.rm=TRUE)
yint_ave <- rowMeans(yint[, y_pval < 0.05/length(y_pval)], na.rm=TRUE)
point_colors <- as.character( brocolors("web")[c("green", "purple")] )
labels <- paste0(names(xint_ave))
iplot(xint_ave, yint_ave, group=sex, indID=labels,
chartOpts=list(pointcolor=point_colors, pointsize=4,
xlab="Average X chr intensity", ylab="Average Y chr intensity"))phetX <- rowSums(gm$geno$X == 2)/rowSums(gm$geno$X != 0)
iplot(xint_ave, phetX, group=sex, indID=labels,
chartOpts=list(pointcolor=point_colors, pointsize=4,
xlab="Average X chr intensity", ylab="Proportion het on X chr"))Sample duplicates
cg <- compare_geno(gm, cores=10)
summary.cg <- summary(cg, threshold = 0)
#get the name and missing percentage
summary.cg$Name.ind1 <- str_split_fixed(summary.cg$ind1, "_",7)[,6]
summary.cg$Name.ind2 <- str_split_fixed(summary.cg$ind2, "_",7)[,6]
summary.cg$miss.ind1 <- percent_missing[match(summary.cg$ind1, names(percent_missing))]
summary.cg$miss.ind2 <- percent_missing[match(summary.cg$ind2, names(percent_missing))]
summary.cg$remove.id <- ifelse(summary.cg$miss.ind1 > summary.cg$miss.ind2, summary.cg$ind1, summary.cg$ind2)
#filter prop_match>=0.85 or same name for Name.ind1 and Name.ind2
filtered.summary.cg <- summary.cg %>%
mutate(same.sample = case_when(
Name.ind1 == Name.ind2 ~ TRUE,
Name.ind1 != Name.ind2 ~ FALSE
)) %>%
filter(prop_match >= 0.85 | same.sample == TRUE)
save(filtered.summary.cg,
file = "data/Jackson_Lab_12_batches/filtered.summary.cg.RData")
#display filtered.summary.cg
DT::datatable(filtered.summary.cg, filter = list(position = 'top', clear = FALSE),
options = list(pageLength = 40, scrollY = "300px", scrollX = "40px"))#plot prop matrix for same.sample = false and prop_match >= 0.85
filter.id <- data.frame(id = unique(c(filtered.summary.cg[filtered.summary.cg$same.sample == F,]$ind1,
filtered.summary.cg[filtered.summary.cg$same.sample == F,]$ind2)))
filter.id$name <- do.call(rbind.data.frame,
strsplit(filter.id$id, "V01_"))[,2]
filter.id <- filter.id[order(filter.id$name),]
gm_filter <- gm[filter.id$id,]
#replace id names
old_ids <- do.call(rbind.data.frame,
strsplit(ind_ids(gm_filter), "V01_"))[,2]
new_ids <- setNames(old_ids,
ind_ids(gm_filter))
gm_filter <- replace_ids(gm_filter, new_ids)
#save gm_filter for same.sample = false and prop_match >= 0.85
save(gm_filter, file = "data/Jackson_Lab_12_batches/gm_filterprop_match_0.85.RData")
#compare geno
filter.cg <- compare_geno(gm_filter, cores=10, proportion = TRUE)
filter.cg[lower.tri(filter.cg)] <- NA
filter.cg[filter.cg < 0.5] <- NA # for ggplot lowest value 0.5
diag(filter.cg) <- 0
# Melt the correlation matrix
melted_cormat <- melt(filter.cg, na.rm = TRUE)
# Heatmap
p <- ggplot(data = melted_cormat, aes(Var2, Var1, fill = value))+
geom_tile(color = "white")+
scale_fill_gradient2(low = "white", high = "red",
limit = c(0.5,1), space = "Lab",
name="Proportions of matching genotypes") +
scale_y_discrete(position = "right") +
xlab("") +
ylab("") +
theme_bw() +
theme(panel.border = element_blank(), panel.grid.major = element_blank(),
panel.grid.minor = element_blank(), axis.line = element_line(colour = "black")) +
theme(axis.text.x = element_text(angle = 90, vjust = 0.5,
size = 10, hjust = 1),
axis.text.y = element_text(size = 10)) +
coord_fixed()
p
| Version | Author | Date |
|---|---|---|
| c1326cd | xhyuo | 2020-11-04 |
pdf(file = "data/Jackson_Lab_12_batches/Proportion_matching_genotypes_before_removal_samples.pdf", width = 20, height = 20)
par(mar=c(5.1,0.6,0.6, 0.6))
hist(cg[upper.tri(cg)], breaks=seq(0, 1, length=201),
main="", yaxt="n", ylab="", xlab="Proportion matching genotypes")
rug(cg[upper.tri(cg)])
dev.off()png
2 par(mar=c(5.1,0.6,0.6, 0.6))
hist(cg[upper.tri(cg)], breaks=seq(0, 1, length=201),
main="", yaxt="n", ylab="", xlab="Proportion matching genotypes")
rug(cg[upper.tri(cg)])
| Version | Author | Date |
|---|---|---|
| c1326cd | xhyuo | 2020-11-04 |
pdf(file = "data/Jackson_Lab_12_batches/Proportion_matching_genotypes_after_removal_samples_percent_missing_5.pdf",width = 20, height = 20)
cgsub <- cg[percent_missing < 5, percent_missing < 5]
par(mar=c(5.1,0.6,0.6, 0.6))
hist(cgsub[upper.tri(cgsub)], breaks=seq(0, 1, length=201),
main="", yaxt="n", ylab="", xlab="Proportion matching genotypes")
rug(cgsub[upper.tri(cgsub)])
dev.off()png
2 cgsub <- cg[percent_missing < 5, percent_missing < 5]
par(mar=c(5.1,0.6,0.6, 0.6))
hist(cgsub[upper.tri(cgsub)], breaks=seq(0, 1, length=201),
main="", yaxt="n", ylab="", xlab="Proportion matching genotypes")
rug(cgsub[upper.tri(cgsub)])
| Version | Author | Date |
|---|---|---|
| c1326cd | xhyuo | 2020-11-04 |
#show samples with missing genotypes >5
miss_dat_5 <- miss_dat %>%
arrange(desc(Percent_missing_genotype_data)) %>%
filter(labels2 != "")
dim(miss_dat_5)[1] 46 6#display miss_dat
DT::datatable(miss_dat_5,filter = list(position = 'top', clear = FALSE),
options = list(pageLength = 40, scrollY = "300px", scrollX = "40px"))Array intensities and Genotype frequencies
#result object is Array intensities 286518*3284
result <- result[seq(1, nrow(result), by=2),-(1:2)] + result[-seq(1, nrow(result), by=2),-(1:2)]
result <- result[,intersect(ind_ids(gm), colnames(result))]
n <- names(sort(percent_missing[intersect(ind_ids(gm), colnames(result))], decreasing=TRUE))
iboxplot(log10(t(result[,n])+1), orderByMedian=FALSE, chartOpts=list(ylab="log10(SNP intensity + 1)"))# Genotype frequencies
g <- do.call("cbind", gm$geno[1:19])
fg <- do.call("cbind", gm$founder_geno[1:19])
g <- g[,colSums(fg==0)==0]
fg <- fg[,colSums(fg==0)==0]
fgn <- colSums(fg==3)
gf_ind <- vector("list", 4)
for(i in 1:4) {
gf_ind[[i]] <- t(apply(g[,fgn==i], 1, function(a) table(factor(a, 1:3))/sum(a != 0)))
}
par(mfrow=c(4,1), mar=c(0.6, 0.6, 2.6, 0.6))
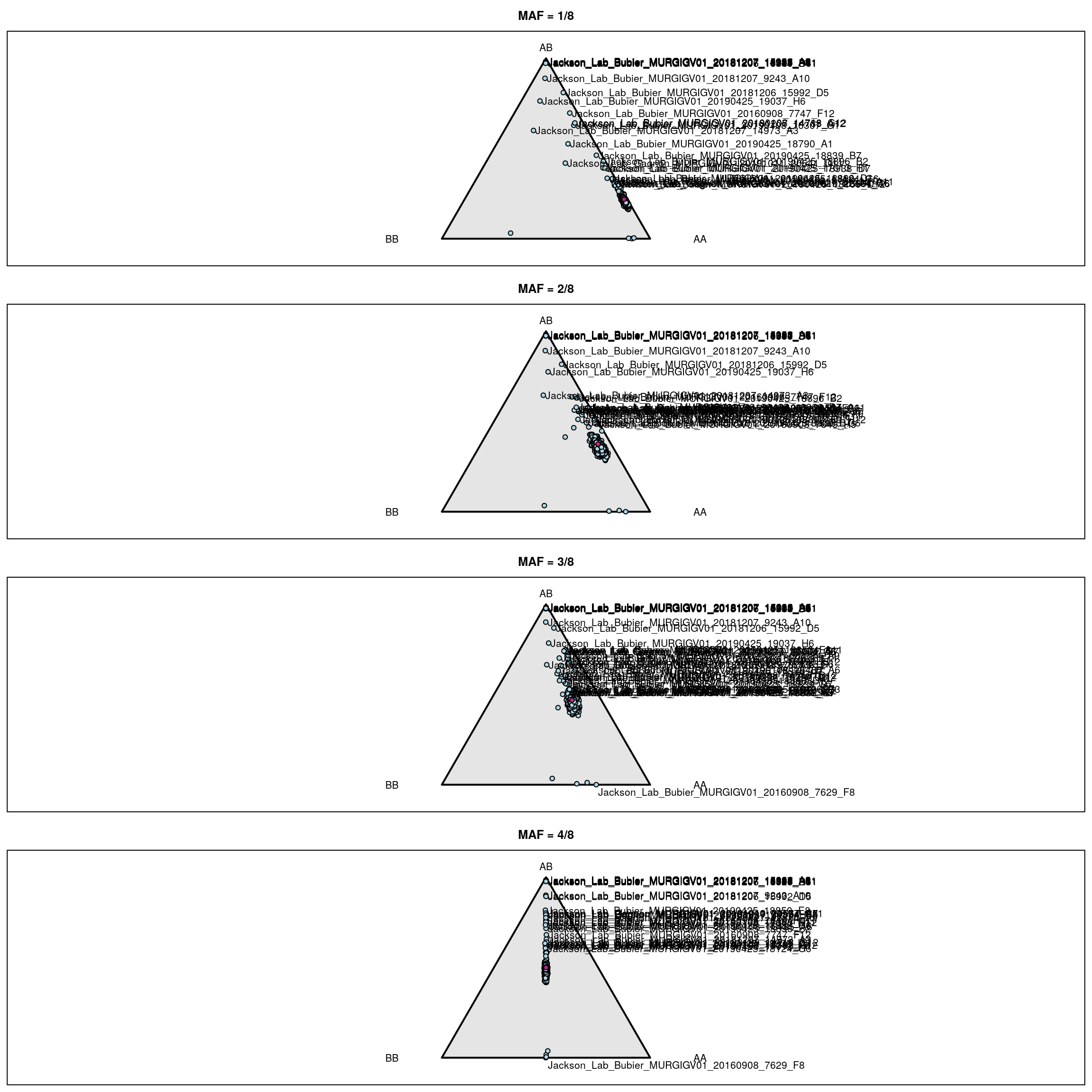
for(i in 1:4) {
triplot(c("AA", "AB", "BB"), main=paste0("MAF = ", i, "/8"))
tripoints(gf_ind[[i]], pch=21, bg="lightblue")
tripoints(c((1-i/8)^2, 2*i/8*(1-i/8), (i/8)^2), pch=21, bg="violetred")
if(i>=3) { # label mouse with lowest het
wh <- which(gf_ind[[i]][,2] == min(gf_ind[[i]][,2]))
tritext(gf_ind[[i]][wh,,drop=FALSE] + c(0.02, -0.02, 0),
names(wh), adj=c(0, 1))
}
# label other mice
if(i==1) {
lab <- rownames(gf_ind[[i]])[gf_ind[[i]][,2]>0.3]
}
else if(i==2) {
lab <- rownames(gf_ind[[i]])[gf_ind[[i]][,2]>0.48]
}
else if(i==3) {
lab <- rownames(gf_ind[[i]])[gf_ind[[i]][,2]>0.51]
}
else if(i==4) {
lab <- rownames(gf_ind[[i]])[gf_ind[[i]][,2]>0.6]
}
for(ind in lab) {
if(grepl("^F", ind) && i != 3) {
tritext(gf_ind[[i]][ind,,drop=FALSE] + c(-0.01, 0, +0.01), ind, adj=c(1,0.5))
} else {
tritext(gf_ind[[i]][ind,,drop=FALSE] + c(0.01, 0, -0.01), ind, adj=c(0,0.5))
}
}
}
| Version | Author | Date |
|---|---|---|
| c1326cd | xhyuo | 2020-11-04 |
Crossover counts and Genotyping error LOD scores
#load pre-caluated results
load("data/Jackson_Lab_12_batches/pr.RData")
load("data/Jackson_Lab_12_batches/m.RData")
load("data/Jackson_Lab_12_batches/nxo.RData")
#crossover
totxo <- rowSums(nxo)[ind_ids(gm)]
all.equal(ind_ids(gm), names(totxo))[1] TRUEiplot(seq_along(totxo),
totxo,
group=gm$covar$ngen,
chartOpts=list(xlab="Mouse", ylab="Number of crossovers",
margin=list(left=80,top=40,right=40,bottom=40,inner=5),
axispos=list(xtitle=25,ytitle=50,xlabel=5,ylabel=5)))#save crossover into pdf
pdf(file = "data/Jackson_Lab_12_batches/number_crossover.pdf")
cross_over <- data.frame(Mouse = seq_along(totxo), Number_crossovers = totxo, generation = gm$covar$ngen)
names(totxo) <- as.character(do.call(rbind.data.frame, strsplit(names(totxo), "V01_"))[,2])
names(totxo)[totxo <= 800 & totxo >= 400] = ""
# Change point shapes and colors
p <-ggplot(cross_over, aes(x=Mouse, y=Number_crossovers, fill = generation, color=generation)) +
geom_point() +
geom_text_repel(aes(label=names(totxo),hjust=0,vjust=0), show.legend = FALSE)
p
dev.off()png
2 p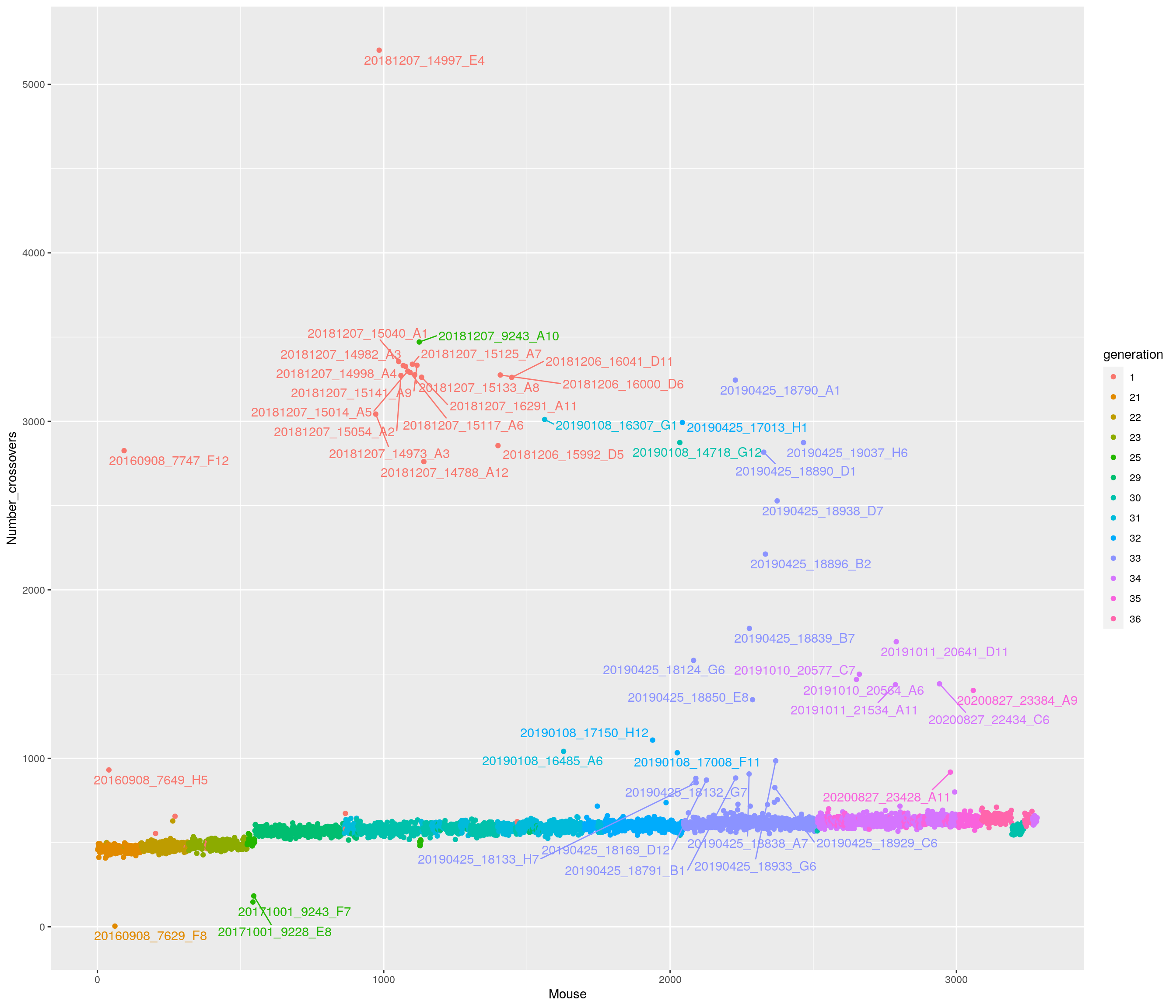
| Version | Author | Date |
|---|---|---|
| c1326cd | xhyuo | 2020-11-04 |
#Here are the crossover counts for those mice with percent_missing >= 5:
tmp <- cbind(percent_missing=round(percent_missing,2), total_xo=totxo)[percent_missing >= 5,]
#display miss_dat
DT::datatable(tmp[order(tmp[,1]),], filter = list(position = 'top', clear = FALSE),
options = list(pageLength = 40, scrollY = "300px", scrollX = "40px"))# Genotyping error LOD scores
load("data/Jackson_Lab_12_batches/e.RData")
errors_ind <- rowSums(e>2)/n_typed(gm)*100
lab <- paste0(names(errors_ind), " (", myround(percent_missing,1), "%)")
iplot(seq_along(errors_ind), errors_ind, indID=lab,
chartOpts=list(xlab="Mouse", ylab="Percent genotyping errors", ylim=c(0, 8),
axispos=list(xtitle=25, ytitle=50, xlabel=5, ylabel=5)))save(errors_ind, file = "data/Jackson_Lab_12_batches/errors_ind.RData")
# Apparent genotyping errors
load("data/Jackson_Lab_12_batches/snpg.RData")
gobs <- do.call("cbind", gm$geno)
gobs[gobs==0] <- NA
par(pty="s")
err_direct <- rowMeans(snpg != gobs, na.rm=TRUE)*100
errors_ind_0 <- rowSums(e > 0)/n_typed(gm)*100
par(mar=c(4.1,4.1,0.6, 0.6))
grayplot(errors_ind_0, err_direct,
xlab="Percent errors (error LOD > 0)",
ylab="Percent errors (obs vs predicted)",
xlim=c(0, 2), ylim=c(0, 2))
abline(0,1,lty=2, col="gray60")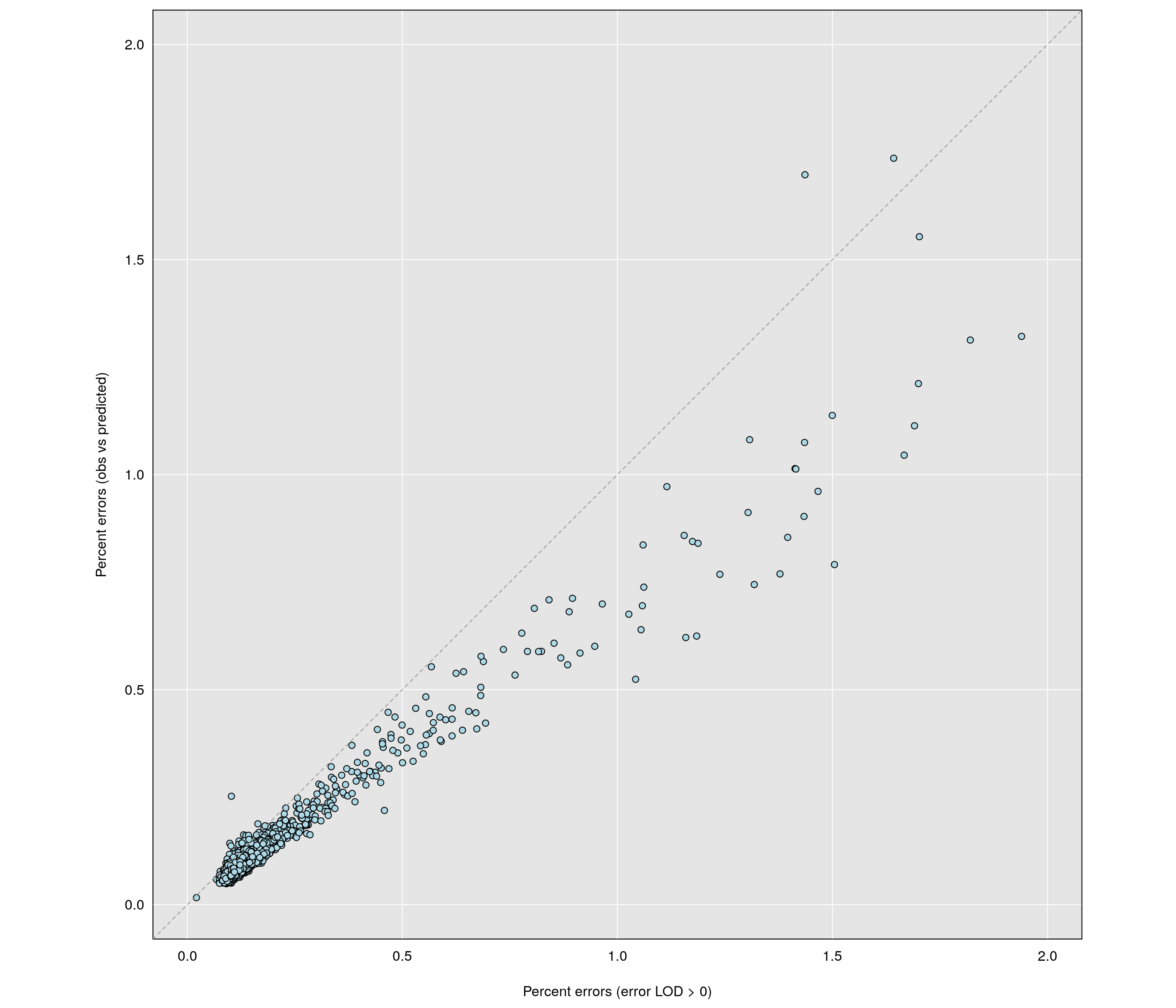
| Version | Author | Date |
|---|---|---|
| c1326cd | xhyuo | 2020-11-04 |
pdf(file = "data/Jackson_Lab_12_batches/Percent_genotype_errors_obs_vs_predicted.pdf",width = 20, height = 20)
par(pty="s")
err_direct <- rowMeans(snpg != gobs, na.rm=TRUE)*100
errors_ind_0 <- rowSums(e > 0)/n_typed(gm)*100
par(mar=c(4.1,4.1,0.6, 0.6))
grayplot(errors_ind_0, err_direct,
xlab="Percent errors (error LOD > 0)",
ylab="Percent errors (obs vs predicted)",
xlim=c(0, 2), ylim=c(0, 2))
abline(0,1,lty=2, col="gray60")
dev.off()png
2 Missing data in Markers and Genotype frequencies Markers
#It can also be useful to look at the proportion of missing genotypes by marker.
#Markers with a lot of missing data were likely difficult to call, and so the genotypes that were called may contain a lot of errors.
pmis_mar <- n_missing(gm, "marker", "proportion")*100
par(mar=c(5.1,0.6,0.6, 0.6))
hist(pmis_mar, breaks=seq(0, 100, length=201),
main="", yaxt="n", ylab="", xlab="Percent missing genotypes")
rug(pmis_mar)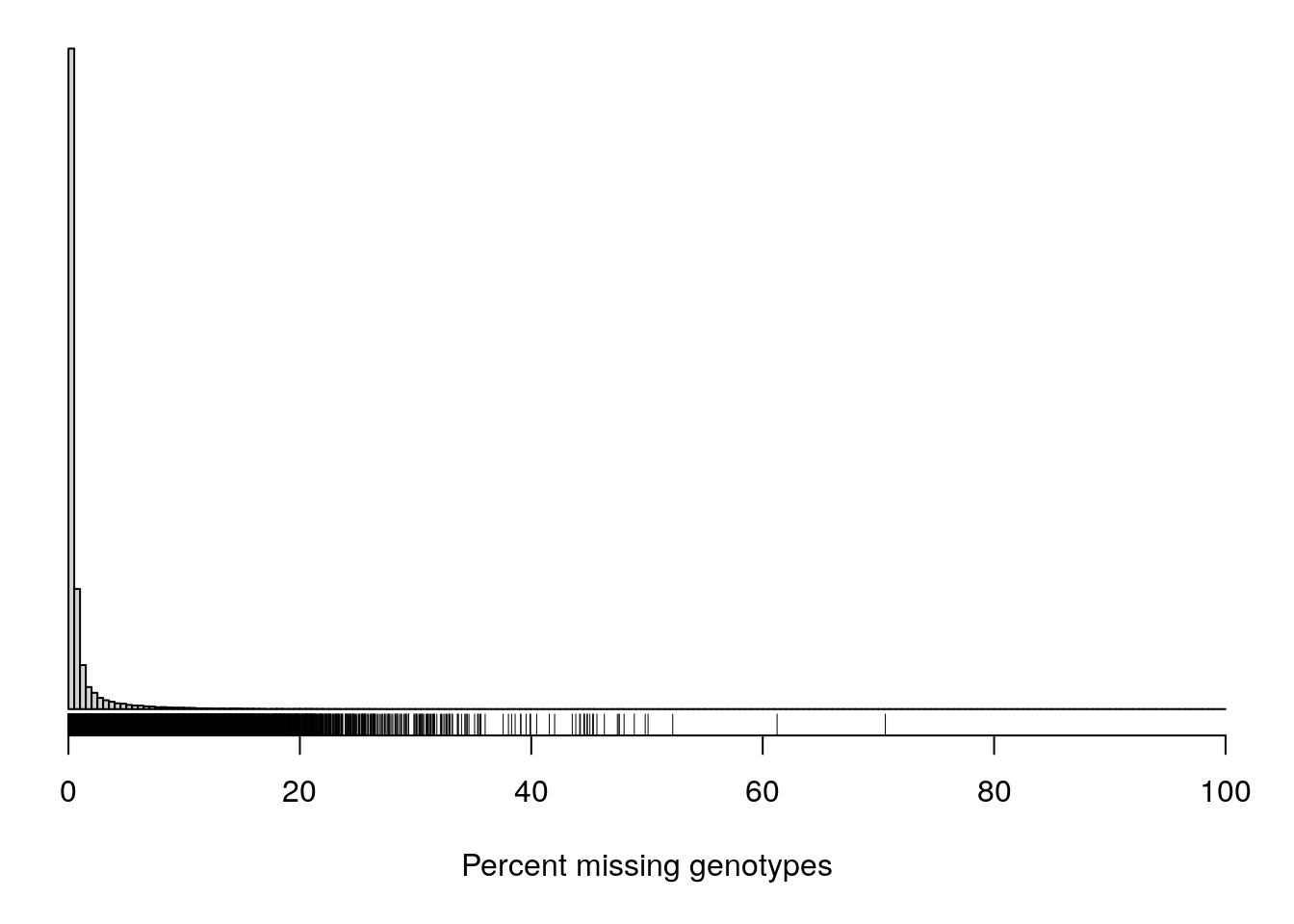
| Version | Author | Date |
|---|---|---|
| c1326cd | xhyuo | 2020-11-04 |
pdf(file = "data/Jackson_Lab_12_batches/Percent_missing_genotype_data_per_marker.pdf")
par(mar=c(5.1,0.6,0.6, 0.6))
hist(pmis_mar, breaks=seq(0, 100, length=201),
main="", yaxt="n", ylab="", xlab="Percent missing genotypes")
rug(pmis_mar)
dev.off()png
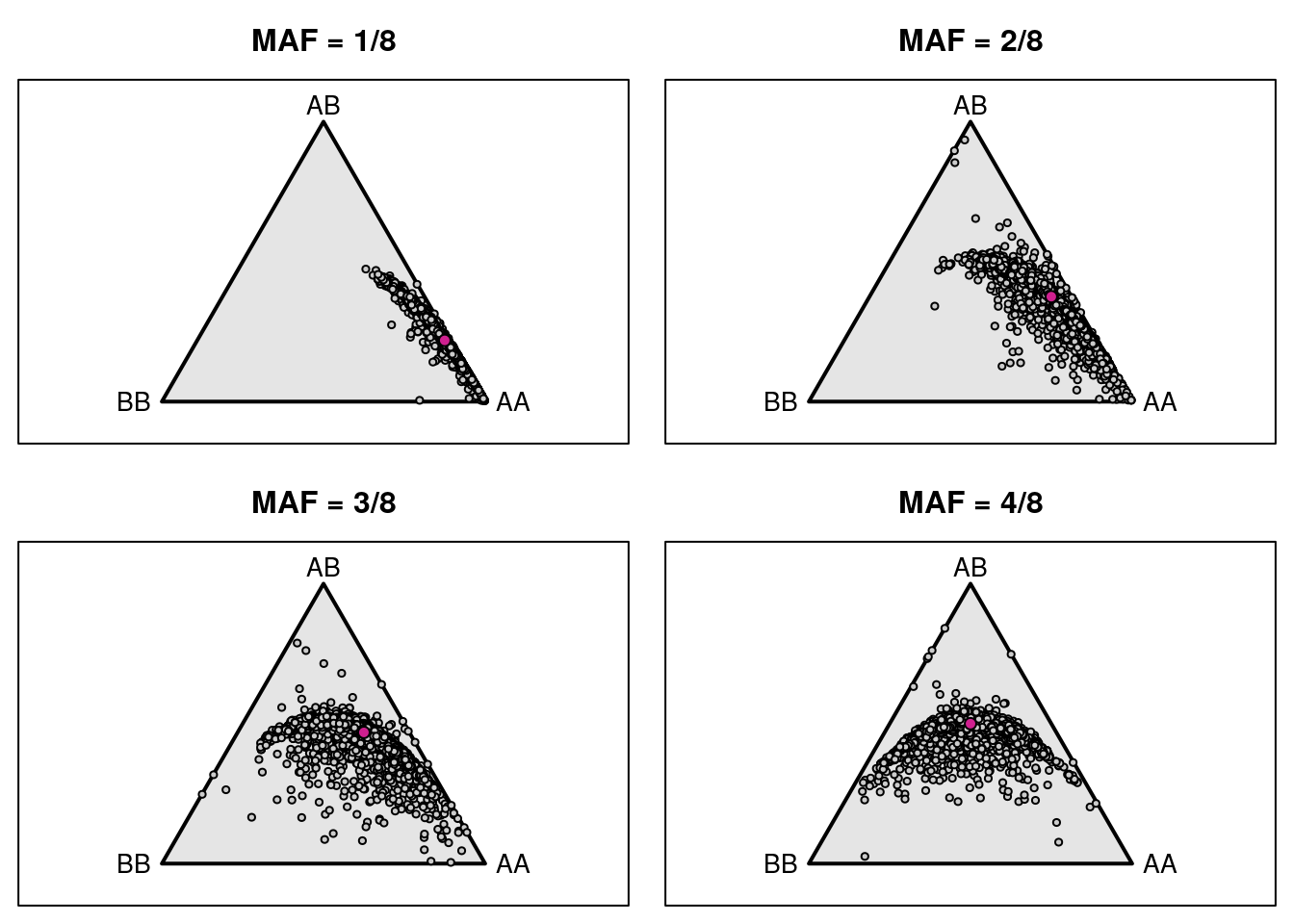
2 # Genotype frequencies Markers
gf_mar <- t(apply(g, 2, function(a) table(factor(a, 1:3))/sum(a != 0)))
gn_mar <- t(apply(g, 2, function(a) table(factor(a, 1:3))))
pdf(file = "data/Jackson_Lab_12_batches/genotype_frequency_marker.pdf")
par(mfrow=c(2,2), mar=c(0.6, 0.6, 2.6, 0.6))
for(i in 1:4) {
triplot(c("AA", "AB", "BB"), main=paste0("MAF = ", i, "/8"))
z <- gf_mar[fgn==i,]
z <- z[rowSums(is.na(z)) < 3,]
tripoints(z, pch=21, bg="gray80", cex=0.6)
tripoints(c((1-i/8)^2, 2*i/8*(1-i/8), (i/8)^2), pch=21, bg="violetred")
}
dev.off()png
2 par(mfrow=c(2,2), mar=c(0.6, 0.6, 2.6, 0.6))
for(i in 1:4) {
triplot(c("AA", "AB", "BB"), main=paste0("MAF = ", i, "/8"))
z <- gf_mar[fgn==i,]
z <- z[rowSums(is.na(z)) < 3,]
tripoints(z, pch=21, bg="gray80", cex=0.6)
tripoints(c((1-i/8)^2, 2*i/8*(1-i/8), (i/8)^2), pch=21, bg="violetred")
}
| Version | Author | Date |
|---|---|---|
| c1326cd | xhyuo | 2020-11-04 |
# Genotype errors Markers
errors_mar <- colSums(e>2)/n_typed(gm, "marker")*100
grayplot(pmis_mar, errors_mar,
xlab="Proportion missing", ylab="Proportion genotyping errors")
pdf(file = "data/Jackson_Lab_12_batches/genotype_error_marker.pdf")
grayplot(pmis_mar, errors_mar,
xlab="Proportion missing", ylab="Proportion genotyping errors")
dev.off()png
2 Remove bad samples
#qc_infor
#percent missing
qc_info <- left_join(gm$covar, miss_dat)Joining, by = "id"#add cross_over
cross_over$id <- rownames(cross_over)
qc_info <- qc_info %>% left_join(cross_over[,-1])Joining, by = "id"#mismatch sex
qc_info <- qc_info %>%
mutate(sex.match = case_when(
predict.sex == sex ~ TRUE,
predict.sex != sex ~ FALSE
))
#genotype errors
qc_info <- qc_info %>%
left_join(
data.frame(id = names(errors_ind),
genotype_erros = errors_ind,stringsAsFactors = F)
)Joining, by = "id"#add duplicated id to be remove
qc_info <- qc_info %>%
mutate(remove.id.duplicated = case_when(
id %in% unique(c(filtered.summary.cg$remove.id)) ~ TRUE,
!(id %in% unique(c(filtered.summary.cg$remove.id))) ~ FALSE
))
#bad sample label
qc_info <- qc_info %>%
mutate(bad.sample = case_when(
(ngen ==1 | Number_crossovers <= 200 | Number_crossovers >=1000 | percent_missing >= 10 | genotype_erros >= 1 | remove.id.duplicated == TRUE) ~ TRUE,
TRUE ~ FALSE
))
save(qc_info, file = "data/Jackson_Lab_12_batches/qc_info.RData")
#display qc_info
DT::datatable(qc_info, filter = list(position = 'top', clear = FALSE),
options = list(pageLength = 40, scrollY = "300px", scrollX = "40px"))#remove bad samples
gm.no.bad <- gm[paste0("-",as.character(qc_info[qc_info$bad.sample == TRUE, "id"])),]
gm.no.badObject of class cross2 (crosstype "do")
Total individuals 3173
No. genotyped individuals 3173
No. phenotyped individuals 3173
No. with both geno & pheno 3173
No. phenotypes 1
No. covariates 5
No. phenotype covariates 0
No. chromosomes 20
Total markers 112729
No. markers by chr:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
8555 8666 6420 6615 6571 6444 6294 5677 5870 5447 6352 5167 5274 5039 4555 4369
17 18 19 X
4330 4002 3108 3974 # subjects
# update other stuff
e <- e[ind_ids(gm.no.bad),]
g <- g[ind_ids(gm.no.bad),]
snpg <- snpg[ind_ids(gm.no.bad),]
length(errors_mar[errors_mar > 5])[1] 259# omit the markers with error rates >5%.
bad_markers <- find_markerpos(gm.no.bad, names(errors_mar[errors_mar > 5]))
save(bad_markers, file = "data/Jackson_Lab_12_batches/bad_markers.RData")
#drop bad markers
gm_after_qc <- drop_markers(gm.no.bad, names(errors_mar)[errors_mar > 5])
gm_after_qcObject of class cross2 (crosstype "do")
Total individuals 3173
No. genotyped individuals 3173
No. phenotyped individuals 3173
No. with both geno & pheno 3173
No. phenotypes 1
No. covariates 5
No. phenotype covariates 0
No. chromosomes 20
Total markers 112470
No. markers by chr:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
8532 8649 6402 6603 6558 6429 6281 5660 5856 5438 6339 5151 5259 5027 4548 4356
17 18 19 X
4322 3986 3103 3971 save(gm_after_qc, file = paste0("data/Jackson_Lab_12_batches/gm_DO", length(ind_ids(gm_after_qc)) ,"_qc.RData"))
save(e,g,snpg, file = "data/Jackson_Lab_12_batches/e_g_snpg_qc.RData")
#replace id
new.id <- str_split_fixed(ind_ids(gm_after_qc), "_",7)[,6]
names(new.id) <- ind_ids(gm_after_qc)
gm_after_qc <- replace_ids(gm_after_qc, new.id)
gm_after_qcObject of class cross2 (crosstype "do")
Total individuals 3173
No. genotyped individuals 3173
No. phenotyped individuals 3173
No. with both geno & pheno 3173
No. phenotypes 1
No. covariates 5
No. phenotype covariates 0
No. chromosomes 20
Total markers 112470
No. markers by chr:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
8532 8649 6402 6603 6558 6429 6281 5660 5856 5438 6339 5151 5259 5027 4548 4356
17 18 19 X
4322 3986 3103 3971 save(gm_after_qc, file = paste0("data/Jackson_Lab_12_batches/gm_DO", length(ind_ids(gm_after_qc)) ,"_qc_newid.RData"))
sessionInfo()R version 4.0.0 (2020-04-24)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 18.04.4 LTS
Matrix products: default
BLAS/LAPACK: /usr/lib/x86_64-linux-gnu/libopenblasp-r0.2.20.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=C
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] DT_0.13 reshape2_1.4.4 forcats_0.5.0 stringr_1.4.0
[5] dplyr_1.0.0 purrr_0.3.4 readr_1.4.0 tidyr_1.1.0
[9] tibble_3.0.1 tidyverse_1.3.0 mclust_5.4.6 DOQTL_1.0.0
[13] ggrepel_0.8.2 ggplot2_3.3.2 qtlcharts_0.12-10 qtl2_0.22-8
[17] broman_0.70-4 workflowr_1.6.2
loaded via a namespace (and not attached):
[1] colorspace_1.4-1 hwriter_1.3.2 ellipsis_0.3.0
[4] rprojroot_1.3-2 corpcor_1.6.9 XVector_0.28.0
[7] GenomicRanges_1.40.0 fs_1.4.1 rstudioapi_0.11
[10] farver_2.0.3 bit64_0.9-7 AnnotationDbi_1.50.3
[13] fansi_0.4.1 lubridate_1.7.9 xml2_1.3.2
[16] knitr_1.28 jsonlite_1.6.1 Rsamtools_2.4.0
[19] broom_0.7.2 annotate_1.66.0 dbplyr_2.0.0
[22] compiler_4.0.0 httr_1.4.1 backports_1.1.6
[25] assertthat_0.2.1 cli_2.0.2 later_1.0.0
[28] org.Mm.eg.db_3.11.4 htmltools_0.4.0 prettyunits_1.1.1
[31] tools_4.0.0 qtl_1.46-2 gtable_0.3.0
[34] glue_1.4.0 GenomeInfoDbData_1.2.3 rappdirs_0.3.1
[37] Rcpp_1.0.4.6 Biobase_2.48.0 cellranger_1.1.0
[40] vctrs_0.3.1 Biostrings_2.56.0 gdata_2.18.0
[43] crosstalk_1.1.0.1 xfun_0.13 rvest_0.3.6
[46] lifecycle_0.2.0 gtools_3.8.2 XML_3.99-0.5
[49] org.Hs.eg.db_3.11.4 zlibbioc_1.34.0 scales_1.1.1
[52] hms_0.5.3 promises_1.1.0 parallel_4.0.0
[55] MUGAExampleData_1.8.0 yaml_2.2.1 curl_4.3
[58] memoise_1.1.0 biomaRt_2.44.4 stringi_1.4.6
[61] RSQLite_2.2.0 S4Vectors_0.26.1 BiocGenerics_0.34.0
[64] BiocParallel_1.22.0 GenomeInfoDb_1.24.2 rlang_0.4.6
[67] pkgconfig_2.0.3 bitops_1.0-6 evaluate_0.14
[70] lattice_0.20-41 labeling_0.4.2 htmlwidgets_1.5.1
[73] bit_1.1-15.2 tidyselect_1.1.0 plyr_1.8.6
[76] magrittr_1.5 R6_2.4.1 IRanges_2.22.2
[79] generics_0.0.2 RUnit_0.4.32 DBI_1.1.0
[82] pillar_1.4.4 haven_2.3.1 whisker_0.4
[85] withr_2.2.0 RCurl_1.98-1.2 QTLRel_1.6
[88] modelr_0.1.8 crayon_1.3.4 BiocFileCache_1.12.1
[91] rmarkdown_2.5 annotationTools_1.62.0 progress_1.2.2
[94] grid_4.0.0 readxl_1.3.1 data.table_1.12.8
[97] blob_1.2.1 git2r_0.27.1 reprex_0.3.0
[100] digest_0.6.25 xtable_1.8-4 httpuv_1.5.4
[103] openssl_1.4.1 stats4_4.0.0 munsell_0.5.0
[106] askpass_1.1