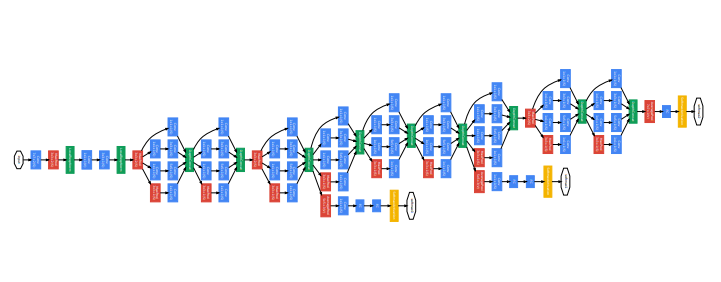
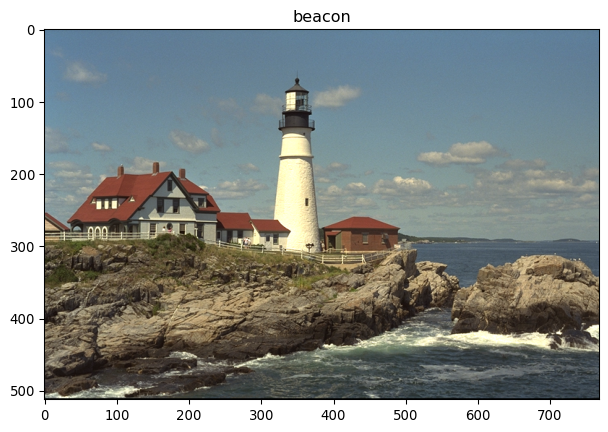
Inception3(
(Conv2d_1a_3x3): BasicConv2d(
(conv): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(Conv2d_2a_3x3): BasicConv2d(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(Conv2d_2b_3x3): BasicConv2d(
(conv): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(maxpool1): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(Conv2d_3b_1x1): BasicConv2d(
(conv): Conv2d(64, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(80, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(Conv2d_4a_3x3): BasicConv2d(
(conv): Conv2d(80, 192, kernel_size=(3, 3), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(maxpool2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(Mixed_5b): InceptionA(
(branch1x1): BasicConv2d(
(conv): Conv2d(192, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch5x5_1): BasicConv2d(
(conv): Conv2d(192, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(48, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch5x5_2): BasicConv2d(
(conv): Conv2d(48, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_1): BasicConv2d(
(conv): Conv2d(192, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_2): BasicConv2d(
(conv): Conv2d(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_3): BasicConv2d(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch_pool): BasicConv2d(
(conv): Conv2d(192, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(Mixed_5c): InceptionA(
(branch1x1): BasicConv2d(
(conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch5x5_1): BasicConv2d(
(conv): Conv2d(256, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(48, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch5x5_2): BasicConv2d(
(conv): Conv2d(48, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_1): BasicConv2d(
(conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_2): BasicConv2d(
(conv): Conv2d(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_3): BasicConv2d(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch_pool): BasicConv2d(
(conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(Mixed_5d): InceptionA(
(branch1x1): BasicConv2d(
(conv): Conv2d(288, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch5x5_1): BasicConv2d(
(conv): Conv2d(288, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(48, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch5x5_2): BasicConv2d(
(conv): Conv2d(48, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_1): BasicConv2d(
(conv): Conv2d(288, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_2): BasicConv2d(
(conv): Conv2d(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_3): BasicConv2d(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch_pool): BasicConv2d(
(conv): Conv2d(288, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(Mixed_6a): InceptionB(
(branch3x3): BasicConv2d(
(conv): Conv2d(288, 384, kernel_size=(3, 3), stride=(2, 2), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_1): BasicConv2d(
(conv): Conv2d(288, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_2): BasicConv2d(
(conv): Conv2d(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_3): BasicConv2d(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(2, 2), bias=False)
(bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(Mixed_6b): InceptionC(
(branch1x1): BasicConv2d(
(conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7_1): BasicConv2d(
(conv): Conv2d(768, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7_2): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7_3): BasicConv2d(
(conv): Conv2d(128, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_1): BasicConv2d(
(conv): Conv2d(768, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_2): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_3): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_4): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_5): BasicConv2d(
(conv): Conv2d(128, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch_pool): BasicConv2d(
(conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(Mixed_6c): InceptionC(
(branch1x1): BasicConv2d(
(conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7_1): BasicConv2d(
(conv): Conv2d(768, 160, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7_2): BasicConv2d(
(conv): Conv2d(160, 160, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7_3): BasicConv2d(
(conv): Conv2d(160, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_1): BasicConv2d(
(conv): Conv2d(768, 160, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_2): BasicConv2d(
(conv): Conv2d(160, 160, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_3): BasicConv2d(
(conv): Conv2d(160, 160, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_4): BasicConv2d(
(conv): Conv2d(160, 160, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_5): BasicConv2d(
(conv): Conv2d(160, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch_pool): BasicConv2d(
(conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(Mixed_6d): InceptionC(
(branch1x1): BasicConv2d(
(conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7_1): BasicConv2d(
(conv): Conv2d(768, 160, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7_2): BasicConv2d(
(conv): Conv2d(160, 160, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7_3): BasicConv2d(
(conv): Conv2d(160, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_1): BasicConv2d(
(conv): Conv2d(768, 160, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_2): BasicConv2d(
(conv): Conv2d(160, 160, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_3): BasicConv2d(
(conv): Conv2d(160, 160, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_4): BasicConv2d(
(conv): Conv2d(160, 160, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_5): BasicConv2d(
(conv): Conv2d(160, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch_pool): BasicConv2d(
(conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(Mixed_6e): InceptionC(
(branch1x1): BasicConv2d(
(conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7_1): BasicConv2d(
(conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7_2): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7_3): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_1): BasicConv2d(
(conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_2): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_3): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_4): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_5): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch_pool): BasicConv2d(
(conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(AuxLogits): InceptionAux(
(conv0): BasicConv2d(
(conv): Conv2d(768, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(conv1): BasicConv2d(
(conv): Conv2d(128, 768, kernel_size=(5, 5), stride=(1, 1), bias=False)
(bn): BatchNorm2d(768, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(fc): Linear(in_features=768, out_features=1000, bias=True)
)
(Mixed_7a): InceptionD(
(branch3x3_1): BasicConv2d(
(conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3_2): BasicConv2d(
(conv): Conv2d(192, 320, kernel_size=(3, 3), stride=(2, 2), bias=False)
(bn): BatchNorm2d(320, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7x3_1): BasicConv2d(
(conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7x3_2): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7x3_3): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7x3_4): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(2, 2), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(Mixed_7b): InceptionE(
(branch1x1): BasicConv2d(
(conv): Conv2d(1280, 320, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(320, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3_1): BasicConv2d(
(conv): Conv2d(1280, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3_2a): BasicConv2d(
(conv): Conv2d(384, 384, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3_2b): BasicConv2d(
(conv): Conv2d(384, 384, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_1): BasicConv2d(
(conv): Conv2d(1280, 448, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(448, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_2): BasicConv2d(
(conv): Conv2d(448, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_3a): BasicConv2d(
(conv): Conv2d(384, 384, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_3b): BasicConv2d(
(conv): Conv2d(384, 384, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch_pool): BasicConv2d(
(conv): Conv2d(1280, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(Mixed_7c): InceptionE(
(branch1x1): BasicConv2d(
(conv): Conv2d(2048, 320, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(320, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3_1): BasicConv2d(
(conv): Conv2d(2048, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3_2a): BasicConv2d(
(conv): Conv2d(384, 384, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3_2b): BasicConv2d(
(conv): Conv2d(384, 384, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_1): BasicConv2d(
(conv): Conv2d(2048, 448, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(448, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_2): BasicConv2d(
(conv): Conv2d(448, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_3a): BasicConv2d(
(conv): Conv2d(384, 384, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_3b): BasicConv2d(
(conv): Conv2d(384, 384, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch_pool): BasicConv2d(
(conv): Conv2d(2048, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(dropout): Dropout(p=0.5, inplace=False)
(fc): Linear(in_features=2048, out_features=1000, bias=True)
)