Integration of ZarrDataset with PyTorch’s DataLoader (Advanced)
import zarrdataset as zds
import torch
from torch.utils.data import DataLoader, ChainDataset
# These are images from the Image Data Resource (IDR)
# https://idr.openmicroscopy.org/ that are publicly available and were
# converted to the OME-NGFF (Zarr) format by the OME group. More examples
# can be found at Public OME-Zarr data (Nov. 2020)
# https://www.openmicroscopy.org/2020/11/04/zarr-data.html
filenames = [
"https://uk1s3.embassy.ebi.ac.uk/idr/zarr/v0.1/6001240.zarr",
"https://uk1s3.embassy.ebi.ac.uk/idr/zarr/v0.1/6001241.zarr",
"https://uk1s3.embassy.ebi.ac.uk/idr/zarr/v0.1/6001242.zarr",
"https://uk1s3.embassy.ebi.ac.uk/idr/zarr/v0.1/6001243.zarr",
]
import random
import numpy as np
# For reproducibility
np.random.seed(478963)
torch.manual_seed(478964)
random.seed(478965)
Extracting patches of size 128x128x32 voxels from a three-dimensional image
Sample the image randomly
patch_size = dict(Z=32, Y=128, X=128)
patch_sampler = zds.PatchSampler(patch_size=patch_size)
Transform the input data from uint16 to float16 with a torchvision pre-processing pipeline
import torchvision
img_preprocessing = torchvision.transforms.Compose([
zds.ToDtype(dtype=np.float16)
])
Pass the pre-processing function to ZarrDataset to be used when generating the samples.
Also, enable return of each patch positions, and the worker ID that generated each patch.
my_datasets = [
zds.ZarrDataset(
[
zds.ImagesDatasetSpecs(
filenames=fn,
data_group="0",
source_axes="TCZYX",
transform=img_preprocessing,
)
],
patch_sampler=patch_sampler,
shuffle=True,
return_positions=True,
return_worker_id=True
)
for fn in filenames
]
Create a ChainDataset from a set of ZarrDatasets that can be put together a single large dataset
my_chain_dataset = ChainDataset(my_datasets)
Make sure the chained_zarrdataset_worker_init_fn function is passed to the DataLoader, so the workers can initialize the dataset correctly
my_dataloader = DataLoader(my_chain_dataset,
num_workers=4,
worker_init_fn=zds.chained_zarrdataset_worker_init_fn,
batch_size=2
)
samples = []
positions = []
wids = []
for i, (wid, pos, sample) in enumerate(my_dataloader):
wids += [w for w in wid]
positions += [p for p in pos]
samples += [s for s in sample]
print(f"Sample {i+1} with size {sample.shape} extracted by worker {wid}.")
if i >= 4:
# Take five batches for illustration purposes
break
samples = torch.cat(samples, dim=0)
samples.shape
Sample 1 with size torch.Size([2, 1, 2, 32, 128, 128]) extracted by worker tensor([0, 0]).
Sample 2 with size torch.Size([2, 1, 2, 32, 128, 128]) extracted by worker tensor([1, 1]).
Sample 3 with size torch.Size([2, 1, 2, 32, 128, 128]) extracted by worker tensor([2, 2]).
Sample 4 with size torch.Size([2, 1, 2, 32, 128, 128]) extracted by worker tensor([3, 3]).
Sample 5 with size torch.Size([2, 1, 2, 32, 128, 128]) extracted by worker tensor([0, 0]).
torch.Size([10, 2, 32, 128, 128])
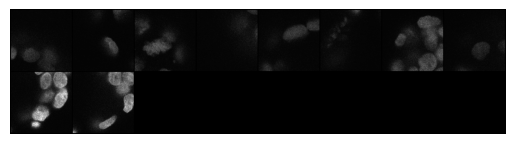
Generate a grid with the sampled patches using torchvision utilities
samples_grid = torchvision.utils.make_grid(samples[:, :, 16, :, :])
import matplotlib.pyplot as plt
plt.imshow(samples_grid[0], cmap="gray")
plt.axis('off')
(np.float64(-0.5), np.float64(1041.5), np.float64(261.5), np.float64(-0.5))
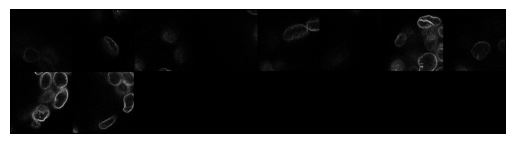
plt.imshow(samples_grid[1], cmap="gray")
plt.axis('off')
(np.float64(-0.5), np.float64(1041.5), np.float64(261.5), np.float64(-0.5))